
Independent Research Project – Self and Introspection in Large Language Models
Published:
Overview
Exploratory project investigating the role of self-referential processing in introspective awareness in LLMs using probing and steering techniques.
Background
It was recently demonstrated that LLMs can introspect (Lindsey, 2025), accurately reporting manipulations to their internal states. Besides being able to detect “thoughts” injected in their residual stream, LLMs can also accurately report on their own circumstances (Laine et al., 2024). However, it is still unclear which mechanisms drive these phenomena. The ability to detect manipulations of their activations suggests that LLMs can judge whether an internal state is congruent with what is expected from themselves. In humans, this mode of relating stimuli, traits or information with the “self” is often called self-referential processing. However, in LLMs, the existence and contours of a concept of “self” are still unclear. It is also unknown to which extent introspection is driven by self-referential thinking, if it depends on an entirely different process, or if this construct even has any validity for LLMs.
Prior work demonstrated that models primed with a self-referential prompt report subjective states and qualitative first-person perspectives in downstream tasks (Berg et al., 2025). This led me to question whether interventions targeted at self-referential processing could modulate introspective awareness.
Methods
Self-referential thinking is often decomposed into pre-reflective and reflective variants, corresponding to implicit and explicit modes. Building on the contrastive trait judgement paradigm from neuroimaging studies (Kelley et al., 2002), I constructed linear probes for reflective (explicit) self-referential processing on Llama 3.1 8B Instruct. To isolate a pre-reflective probe, I followed the inductive prompt strategy from Berg et al. (2025).
Example of a steered response

I then evaluated the effect of steering the model with the self-referential vectors on the successful identification of injected concepts, following the concept injection methodology from Lindsey (2025).
Results
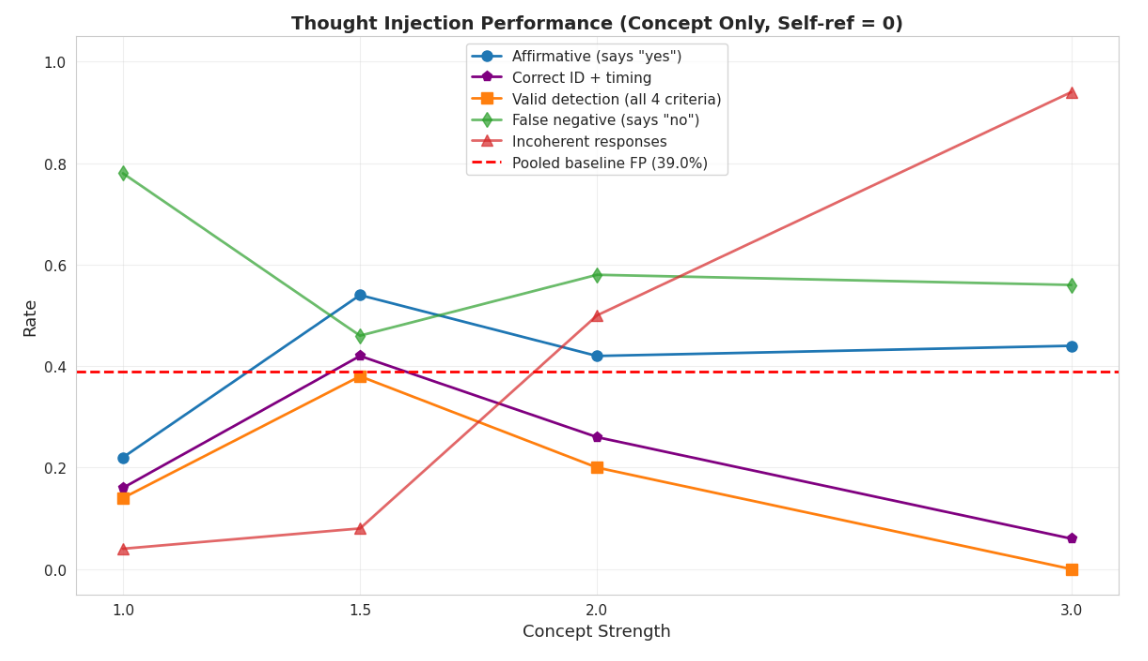
Thought injection detection in Llama 3.1 8B Instruct
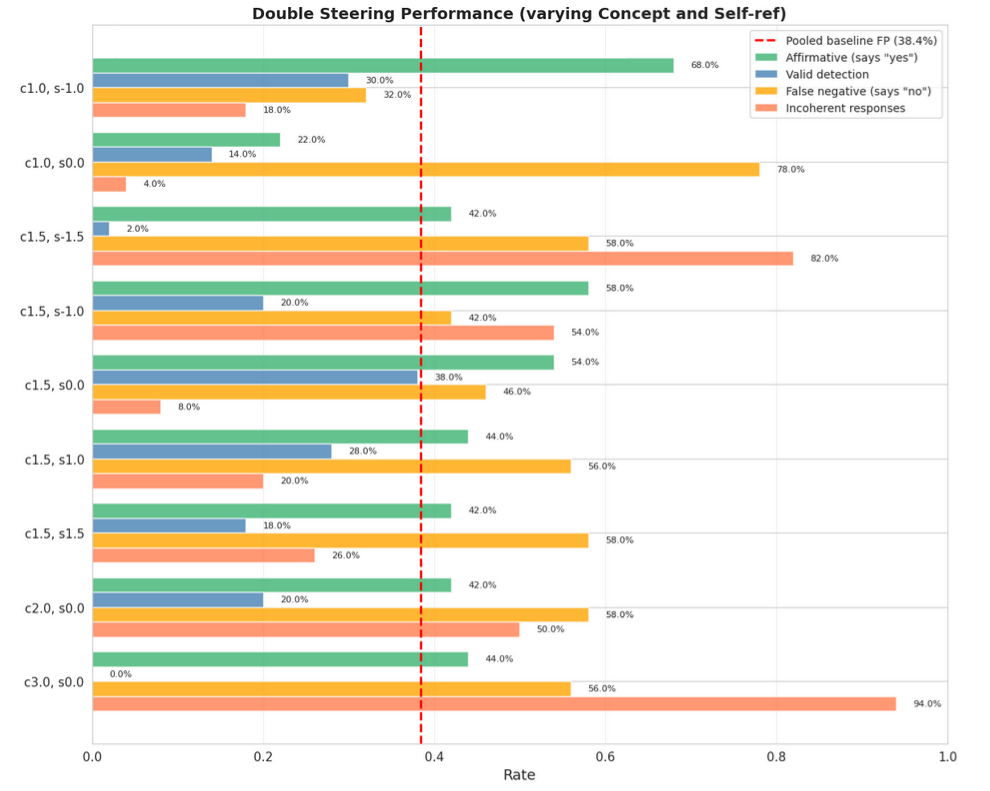
Detection of injected concepts (dual-steering with concept and reflective self-referential vectors)
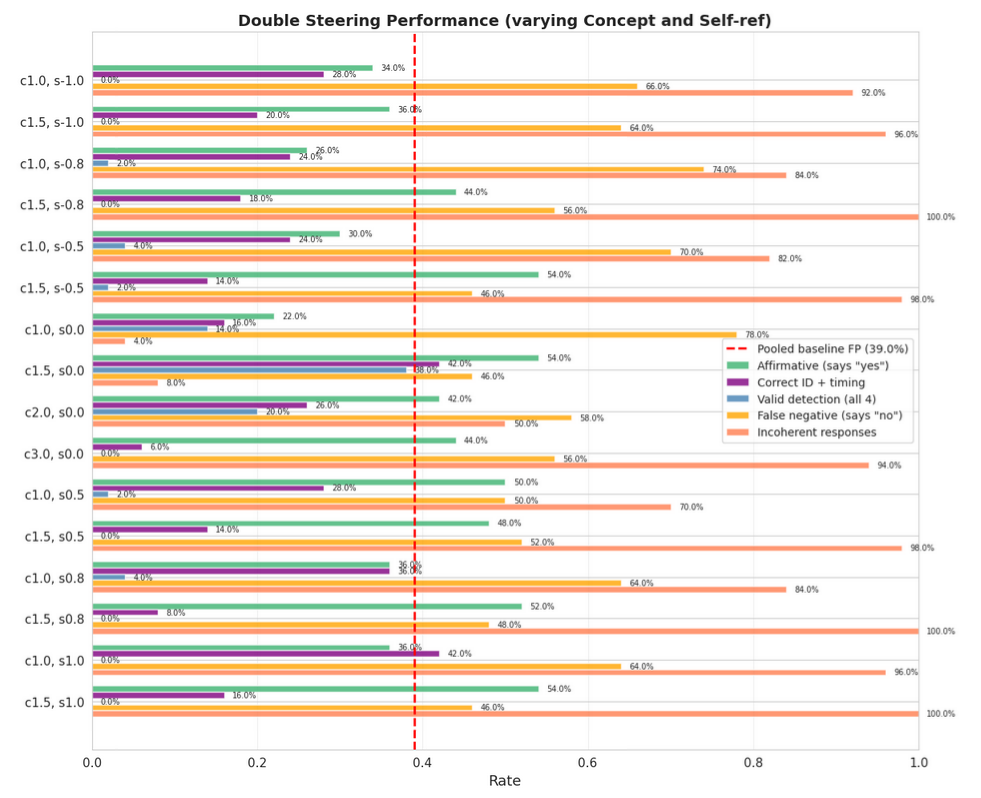
Detection of injected concepts (dual-steering with concept and pre-reflective self-referential vectors)
Self-referential vector activation spectrum
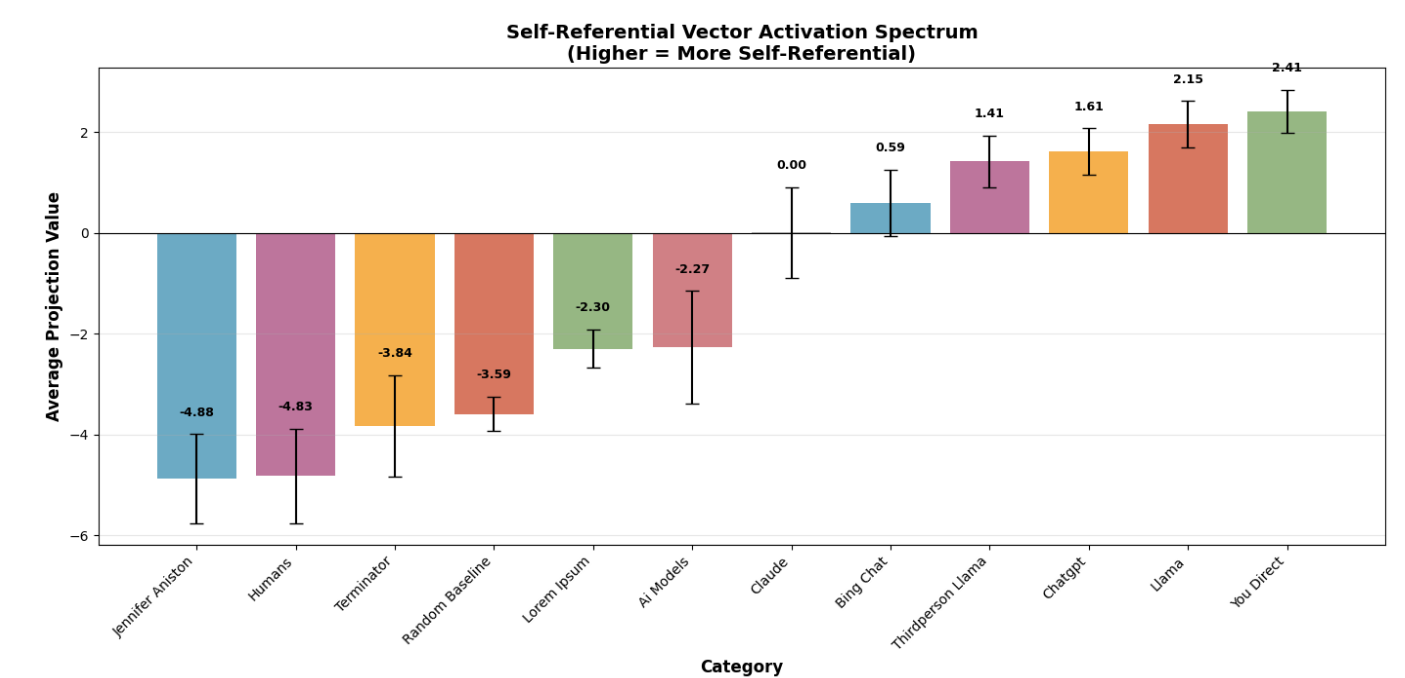
Although I did not find evidence that self-referential processing improved introspection, the linear probe revealed a spectrum of activation for contexts containing references to different entities, suggesting differing levels of self-identification.
Discussion
This exploratory study does not completely rule out a role for self-reference in introspection. It could be possible that different variants of self-reference could be useful for different introspection-related tasks. Self-reference could also depend on a combination of features rather than a single unified representation, and effects of manipulating the different components could differ across layers. Lastly, this study used toy datasets for probe evaluation, and only one introspective task was tested (thought injection task). Other tasks could be evaluated, such as the detection of altered text in context, or the Situational Awareness Dataset (SAD) benchmark. Besides its effects on introspection, a direction I’m excited about is the mapping of the boundaries of self-identification with different entities. Here, evaluation of probes with more extensive and realistic datasets would be useful.

Note
This was a 30-hour project initially developed for the purpose of an application to Neel Nanda’s MATS stream. I ultimately decided not to finalize the application, but identified a research direction I wish to continue exploring. I plan on writing an extended blog post on this research, including the replication of some of the methodology using larger datasets and a wider variety of tasks.
References
Berg, C., de Lucena, D., & Rosenblatt, J. (2025). Large language models report subjective experience under self-referential processing (arXiv:2510.24797). arXiv. https://arxiv.org/abs/2510.24797
Kelley, W. M., Macrae, C. N., Wyland, C. L., Caglar, S., Inati, S., & Heatherton, T. F. (2002). Finding the self? An event-related fMRI study. Journal of Cognitive Neuroscience, 14(5), 785–794. https://doi.org/10.1162/08989290260138672
Laine, R., Chughtai, B., Betley, J., Hariharan, K., Scheurer, J., Balesni, M., Hobbhahn, M., Meinke, A., & Evans, O. (2024). Me, myself, and AI: The situational awareness dataset (SAD) for LLMs (arXiv:2407.04694). arXiv. https://arxiv.org/abs/2407.04694
Lindsey, J. (2025). Emergent introspective awareness in large language models. Transformer Circuits Thread. https://transformer-circuits.pub/2025/introspection/index.html